Вначале были точки и тире, и морзянка витала над бездною. Аналого-цифровое преобразование текста в сигнал выполнялось рукой передающего телеграфиста, обратное аналого-цифровое - ухом принимающего. Вопрос кодировки не стоял.
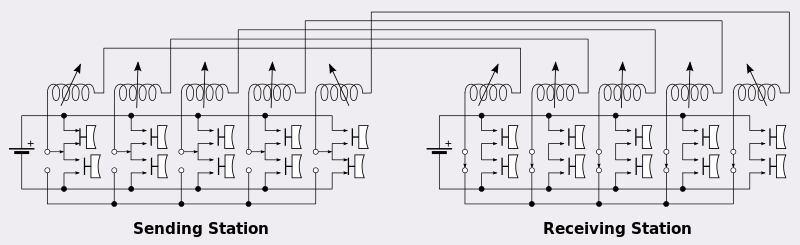
К 1870-м годам Эмиль Бодо переизобрёл велосипед, и пятибитная кодировка массово пошла в народ. К 1900-м годам Дональд Мюррей придумал переносить текст через перфоленту, и добавил коды переключения регистров, чтобы передавать не только буквы, но и цифры и знаки препинания.

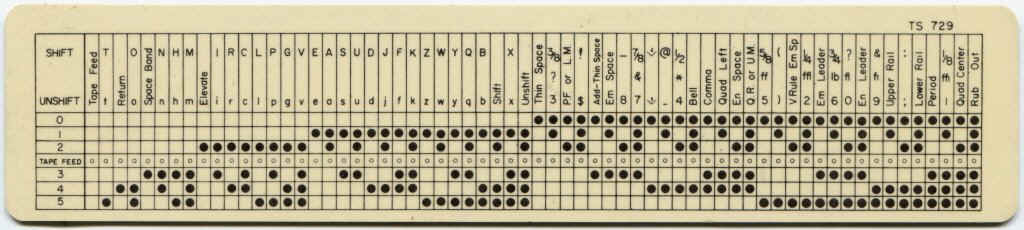
Когда появились компьютеры, к ним быстро приспособили всё наработанное к этому времени телеграфное оборудование: телетайпы, перфораторы и прочее. Многие ранние компьютеры начинали с шестибитных байтов. К примеру, на БЭСМ-6 имена в объектных файлах была представлены в 6-битном коде TEXT. В машинном слове помещалось восемь символов, чего было вполне достаточно по тем временам.


Решение пришло из проекта Plan 9. Дадим каждому символу 32 бита, но упакуем их компактно в 8-битные байты. Получилась кодировка UTF-8, на которую в последние пятнадцать лет все и перешли.

В 32-битном пространстве можно не стесняться. Народ продолжает запихивать в Unicode всё более и более забавные символы.

5-bit
В 1830х годах в электрическом телеграфе Кука и Уитстона было применено 5-битное кодирование букв латинского алфавита посредством стрелок, поворачивавшихся под действием магнитного поля. Понятно, почему пять бит: необходимый минимум, чтобы передать 26 латинских букв.К 1870-м годам Эмиль Бодо переизобрёл велосипед, и пятибитная кодировка массово пошла в народ. К 1900-м годам Дональд Мюррей придумал переносить текст через перфоленту, и добавил коды переключения регистров, чтобы передавать не только буквы, но и цифры и знаки препинания.
6-bit
Кодировка Мюррея была вполне компактной, но потребности росли. Народ хотел передавать не только новостные сообщения, но и газеты целиком. Большие-маленькие буквы, типографские символы, разметку текста и прочие ништяки. В 1928 году придумали и к 1950-м стали массово применять шестибитную кодировку.Когда появились компьютеры, к ним быстро приспособили всё наработанное к этому времени телеграфное оборудование: телетайпы, перфораторы и прочее. Многие ранние компьютеры начинали с шестибитных байтов. К примеру, на БЭСМ-6 имена в объектных файлах была представлены в 6-битном коде TEXT. В машинном слове помещалось восемь символов, чего было вполне достаточно по тем временам.
7-bit
Проблема с шестью битами в том, что в них не удаётся без свистоплясок уместить минимально нужное количество символов, хотя бы от печатной машинки. В 1960-х годах получил распространение и был утверждён стандарт ASCII, ставший с тех пор "таблицей умножения" для всех компьютерщиков.8-bit
Одних латинских букв маловато будет. Большинство европейских языков, даже основанных на латинице, имеет массу других букв. Не говоря уже про кириллицу, греков, армян, грузин и прочих обособленцев. Довольно быстро возникла идея расширить семибитный ASCII другими буквами для разных языков. На настоящий момент известно несколько сотен таких кодировок.
Unicode
Довольно скоро стало понятно, что 8-битное представление символов не решает задачу. Во-первых, китайские, японские и корейские иероглифы остались за бортом. А также арабские, индийские и другие языки. Во-вторых, даже для тех кто поместился в 8 бит, встаёт проблема перекодировок. Всякая программа, даже тривиальная сортировка строк, обязана знать и уметь перекодировать все кодировки, а их количество продолжает расти.Решение пришло из проекта Plan 9. Дадим каждому символу 32 бита, но упакуем их компактно в 8-битные байты. Получилась кодировка UTF-8, на которую в последние пятнадцать лет все и перешли.
В 32-битном пространстве можно не стесняться. Народ продолжает запихивать в Unicode всё более и более забавные символы.
