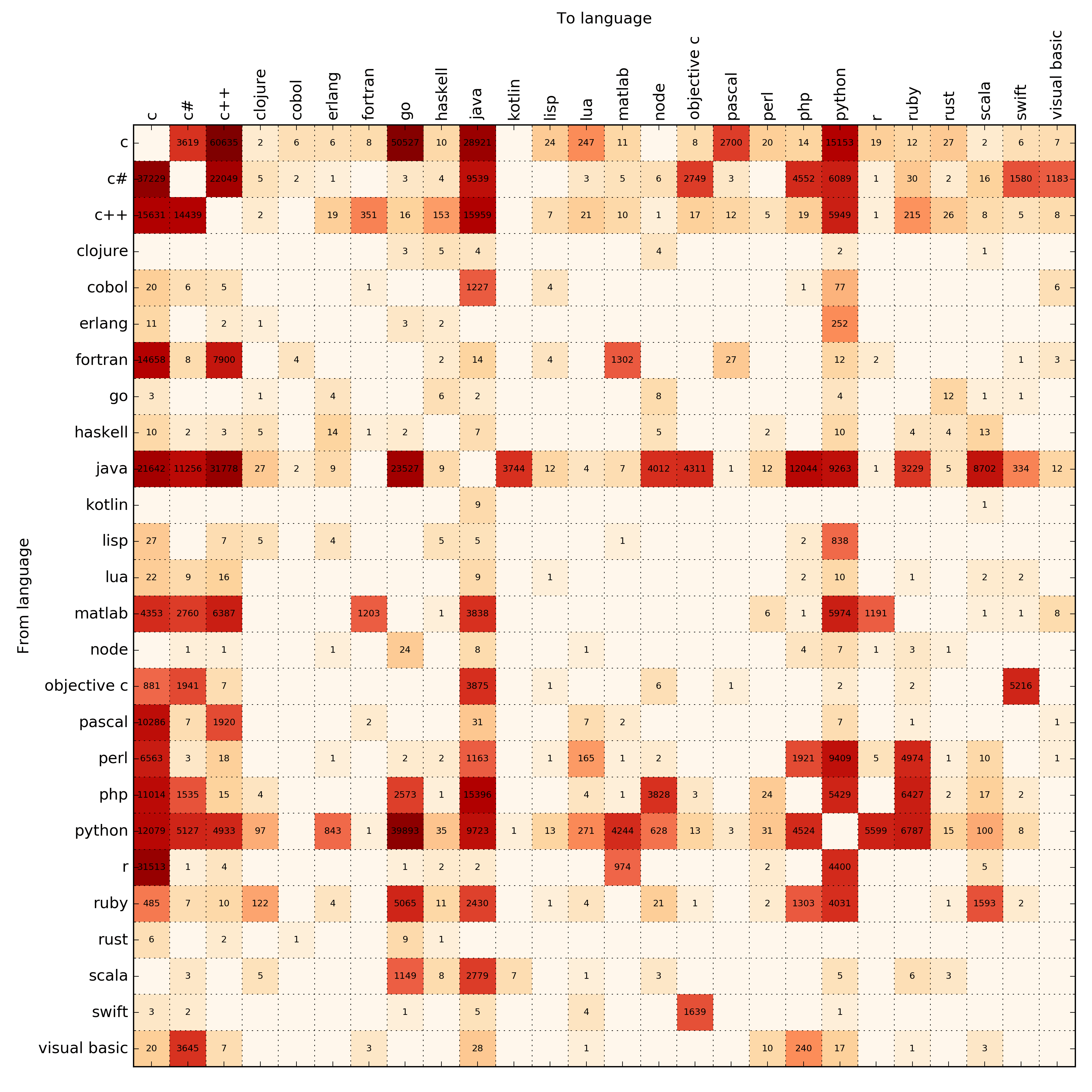
Утилита
Lex была придумана как способ эффективно применять набор регулярных выражений к входному потоку. Когда у нас одно регулярное выражение - используем grep. Но если их несколько, эффективнее будет применить Lex. В документации на Flex есть пример кода, подсчитывающего количество строк, слов и символов во входном потоке, как wc. Вот тот же пример, переписанный для языка
Go и утилиты
nex:
/\n/ {
lval.nline++ // Количество строк
lval.nchar++
}
/[^ \t\n]+/ {
lval.nword++ // Количество слов
lval.nchar += len(yylex.Text())
}
/./ {
lval.nchar++ // Количество символов
}
//
package main
import (
"fmt"
"os"
)
type yySymType struct { // В этой структуре накапливаем результат
nline int
nchar int
nword int
}
func main() {
var result yySymType
lex := NewLexer(os.Stdin) // Сканируем стандартный ввод
lex.Lex(&result)
fmt.Printf("Lines: %d\n", result.nline)
fmt.Printf("Words: %d\n", result.nword)
fmt.Printf("Chars: %d\n", result.nchar)
}
Первая половина файла, до строчки //, задаёт обработку входного потока. В структуре yySymType обычно возвращается информация о следующей лексеме для Yacc, но здесь мы используем её для накопления информации о входном потоке.
Чаще всего Lex используют в связке с Yacc для построения синтаксических анализаторов, но это вовсе необязательно. Массу пользы можно извлечь из Lex самого по себе.
Nex представляет собой тот же Lex, но переписанный на язык Go. Исходники и описание здесь:
https://github.com/blynn/nex. Устанавливается Nex командой:
go get github.com/blynn/nex
Бинарник оказывается в каталоге ~/go/bin/nex
Компилируем и запускаем вышеприведённый код. Утилитой nex обрабатываем входной файл wc.nex, генерится файл с кодом на Go: wc.nn.go. Компилируем его и запускаем:
$ nex wc.nex
$ go build wc.nn.go
$ ./wc.nn < /etc/fstab
Lines: 12
Words: 88
Chars: 675
Сравниваем результат со стандартной утилитой wc:
$ wc /etc/fstab
12 88 675 /etc/fstab