Удачный язык Scala: хочешь пиши в функциональном стиле, а хочешь - в традиционном процедурном, на выбор. Сравним два стиля на примере упомянутой задачки Two-Sum.
Функциональный стиль, так называемый "однострочник":
Мне по жизни доводилось решать задачки в функциональном стиле. Делали мы однажды девайс для передачи данных, и надо было научить его тестировать линию связи. Для этого на девайсе нажимается кнопочка, и такой же девайс на удалённом конце линии включает "шлейф" - принятые от нас данные заворачивает обратно к нам. Нужен простой способ послать команду удалённому девайсу, не вмешиваясь в основной поток данных. Имелся медленный однобитовый канал out-of-band. Решение было послать по этому последовательному каналу псевдослучайный поток, сформированный сдвиговым регистром с обратной связью (LSFR).
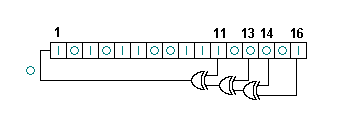
Математически LSFR выглядит как двоичный полином, к примеру x16+x14+x13+x11+1. Чтобы выбрать подходящий к ситуации полином, я быстренько сбацал код на Scheme, и через час решение было найдено.
Через пару лет мы разработали другое устройство, для гораздо более скоростных линий связи, но с другим характером помех в линии. Старые полиномы больше не подходили: наблюдались ложные срабатывания. Надо было подобрать другие полиномы, подлиннее. Достал я старый код и... убил пару дней, пытаясь в нём разобраться. Плюнул, переписал на Си, и код стал понятным.
Перефразируя Форреста Гампа, это всё, что я могу сказать о моём отношении к функциональному программированию. 😀
Функциональный стиль, так называемый "однострочник":
def twoSum(nums: Array[Int], target: Int): Array[Int] = {
nums.zipWithIndex.combinations(2).find(_.map(_(0)).sum == target).get.map(_(1))
}
def twoSum(nums: Array[Int], target: Int): Array[Int] = {
for (j <- nums.indices) {
for (i <- 0 until j) {
if (nums(i) + nums(j) == target) {
return Array(i, j)
}
}
}
throw Exception("no solution")
}
Мне по жизни доводилось решать задачки в функциональном стиле. Делали мы однажды девайс для передачи данных, и надо было научить его тестировать линию связи. Для этого на девайсе нажимается кнопочка, и такой же девайс на удалённом конце линии включает "шлейф" - принятые от нас данные заворачивает обратно к нам. Нужен простой способ послать команду удалённому девайсу, не вмешиваясь в основной поток данных. Имелся медленный однобитовый канал out-of-band. Решение было послать по этому последовательному каналу псевдослучайный поток, сформированный сдвиговым регистром с обратной связью (LSFR).
Математически LSFR выглядит как двоичный полином, к примеру x16+x14+x13+x11+1. Чтобы выбрать подходящий к ситуации полином, я быстренько сбацал код на Scheme, и через час решение было найдено.
Через пару лет мы разработали другое устройство, для гораздо более скоростных линий связи, но с другим характером помех в линии. Старые полиномы больше не подходили: наблюдались ложные срабатывания. Надо было подобрать другие полиномы, подлиннее. Достал я старый код и... убил пару дней, пытаясь в нём разобраться. Плюнул, переписал на Си, и код стал понятным.
Перефразируя Форреста Гампа, это всё, что я могу сказать о моём отношении к функциональному программированию. 😀

no subject
Date: 2022-12-20 01:54 (UTC)Зараз попав в команду, де основні процедури роботи з даними написані на Скалі, але не надто задокументовані, а людей, які писали код, часто вже поряд нема. Моя роль -- чи то методологічний начальник, чи то glorified к'юей, словом, треба розібратися, як воно все у них працює. І що виходить: прочитати скальний код, щоби точно сказати, що там у них під кришкою капота, ніхто ніфіга не може. Ну добре, я, який після C і фортрана щось писав уже на матлабах і пітонах, але ж самі девелопери в тому плавають. Був би нормальний SQL, я би розібрався сам, а так виходить, що вони, з одного боку, всі такі горді "у нас все функціонально і масштабується", а, з другого боку, розібратися, як хоч щось в їхньому аналізі покращити, займає стільки часу, що ніякої радості. Вони, в результаті, навіть власні ідеї переписують часом з нуля, замість поправити готову функцію.
Все як з іншими споживчими продуктами: там, де раніше було трохи довше і незґрабніше зроблено, зате працювало довго і ремонтувалося, зараз все дешевше і гарніше, але як тільки що не так, доводиться викидати старе і купувати нове.
no subject
Date: 2022-12-20 02:08 (UTC)В скале много разных культур. Есть древние. Есть новые (их две, Cats и Zio). И есть разного рода сумасшедшие. Одни лезут со свободными монадами (не зная теории категорий, не знают и, что они не всегда существуют), другие пишут просто код в одну строчку - тест-то писать лень.
Короче, я думаю, можно к скале подходить как к любому нормальному языку: - давай читабельность - давай покрытие тестами - желательно унификацию библиотек, чтобы не было пять разных парсеров джейсона
Преимущество скалы не в том, чтобы писать заумный бред, а в том, что можно писать чистенький код разборчиво и без мусора.
no subject
Date: 2022-12-20 05:53 (UTC)Код-то не якийсь перформанс комп'ютейшн, а робота з даними, з кількома конкретними таблицями, кожна з яких досить унікальна. Проблема нечитабельності в тому, що в процесі абстрагування тих чи інших процедур і використання додаткових бібліотек, маскується розуміння того, які саме дані ми сюди притягнули, що групуємо, що фільтруємо, що лишаємо, як є.
Тобто, тут суть не в тому, як вони закодували, а в тому, що для читабельності з точки зору дата сайєнтіста такий код треба було з усіх сторін обзадокументувати ("а інпути у нас бувають такі, а типові аутпути сякі" і т. п.)
no subject
Date: 2022-12-20 11:58 (UTC)Да это тоже верно.
Насчет же библиотек - вечная тема в скальной среде. Можно ли уже на 13-ю переходить, или таки у нас вот та библиотека не работает с 13-й, а зачем нам та, если есть эта, а есть и эта... Короче, иногда кажется, что проще вообще свой код написать и не мучаться. Видел и свою версию Спарка, в предыдущей конторе, и свою версию Сваггера (в этой конторе) - но со Сваггером, похоже, такая фигня, что мы и мейнтейнеры, только этого никто не помнит.
no subject
Date: 2022-12-20 18:46 (UTC)no subject
Date: 2022-12-20 03:30 (UTC)no subject
Date: 2022-12-20 04:33 (UTC)(disclaimer: часом, читаючи власний код кількарічної давності, я думаю так само... але я, принаймні, коментую. А вони думають, що пишуть в self-documenting парадигмі, а потім читають власний код:
(Я): "А що це у вас тут?"
(вони): "А це ми тут берем результати такого-то метода з ... дивимося...дивимося... такої-то бібліотеки."
(Я): "А що той метод робить? Які там входи/виходи (типові значення, макс/мін, все таке, data science, не псячий хвіст -- у нас весь код про те, як десь взяти якісь дані, схрестити їх з іншими даними, якось перетворити/пофільтрувати/згрупувати, і повернути назад)?"
(вони): "Ой, не знаємо, це ХХХ написав, він уже тут не працює."
(Я): "Ну то подивіться, хто у нас тут Скалу любить і захищає?"
Вони лізуть в тут бібліотеку, а там такий самий самозадокументований код, і хрін його знає, що там таке...
Зате "scalable solution, would be much uglier in SQL". Щаз!
no subject
Date: 2022-12-20 12:00 (UTC)Well, talking about SQL, I'm afraid most programmers, object-oriented or functional, just don't get SQL. Can't explain it, but they don't.
no subject
Date: 2022-12-20 18:25 (UTC)Просто, мова, де дуже зручно писати і читати взаємодію з даними, збереженими в relational форматі.
Якщо треба щось з цими даними робити, воно в сіквелі не завжди найзручніше. Але -- "і читати" :)